2006. 03. 『문화콘텐츠 입문』, 북코리아
하이퍼텍스트 구현 기술
1. 하이퍼텍스트란 무엇인가?
1) 하이퍼텍스트의 개념
하이퍼텍스트(Hyper Text)란 “문서 내의 중요한 키워드마다 다른 문서 또는 유관한 시청각 자료로 연결되는 통로를 만들어 여러 개의 문서가 하나의 문서인 것처럼 보여 주는 문서 형식”을 말한다. 인문 지식 콘텐츠를 개발할 때 “하이퍼텍스트”를 고려해야 하는 이유는 무엇인가? 하이퍼텍스트는 인터넷이라고 하는 새로운 지식 유통의 환경에서 가장 강력한 영향력을 발휘하는 정보 구성 형태이기 때문이다.
컴퓨터가 숫자를 다루던 기계에서 벗어나 문자와 영상, 음향 등을 저장하고 전송할 수 있게 되면서, “책”이라고 하는 매체에 담겨 있는 다양한 종류의 지식들이 전자적인 매체로 옮겨 가게 되었다. 과거 종이에 기록되었던 정보들을 컴퓨터를 통해 처음 접할 수 있게 되었을 때, 그 새로운 책의 장점으로 주목받았던 것은 저장 공간의 획기적 절감, 데이터 접근의 신속성, 텍스트와 멀티미디어 데이터의 복합적 활용 가능성, 정보 검색의 효율성 등이었다. 전자 책의 이러한 장점들은 지식의 전달과 활용의 측면에서 종이 책의 한계를 극복한 커다란 변화로 인식되었다. 그러나 전자 매체가 가져 온 더 큰 변화는 단순히 지식 유통의 편의성을 증진시킨 데 있는 것이 아니라, 지식의 기술 형태를 변화시키고 나아가 그 내용마저도 과거와는 다른 것을 지향하게 만든 데 있다고 할 수 있다.
종이 책은 그 내용을 이루는 지식 요소가 고정되어 있을 뿐 아니라, 그 요소들의 나열 순서가 저자의 기획에 따라 일정하게 확립되어 있어서, 독자는 그 정해진 순서에 따라 책 속의 지식과 정보를 전수하게 된다. 설사 독자가 저자의 의도와는 달리 그 책의 이 부분 저 부분을 임의로 읽어 간다 해도 그것은 저자가 미리 일정한 틀 속에 남아 놓은 지식을 부분적으로 탐색하는 것에 지나지 않는다. 반면 하이퍼텍스트의 세계에서는 독자의 관심이 어디를 향하느냐에 따라 그가 얻게 될 지식과 정보의 내용이 판이하게 달라질 수 있다.
2) 하이퍼텍스트의 특성
하이퍼텍스트의 특성을 이해하기 위해 다음의 예시를 보기로 하자.
<그림 1: 관련 정보의 연결 고리>
위에서 보인 도표는 “청계산”에 관한 기사에 담긴 내용 요소들과 그 각각의 요소와 관련이 있는 정보들의 관계를 도시한 것이다. 만일 이 기사의 저자가 위에 나열한 모든 요소들을 자기 글 속에 포함시키고자 한다면 그 결과물은 원고지 수십매에 달하는 방대한 분량이 될 것이다. 하지만 위에 나열된 유관 정보들의 기사가 이미 어디엔가 존재하고 있고, 그것들을 쉽게 연결해서 볼 수 있다면, “청계산”에 대한 기사는 원고지 1~2 매의 분량으로도 충분할 수 있다. 또한 후자의 경우, 독자들은 그의 개인적 관심이 모아지는 방향에 따라 상이한 줄거리의 지식을 접할 수도 있다. 똑같이 “청계산”을 출발점으로 삼았다 하더라도, 어떤 경우에는 ‘청계산의 주봉인 망경대’ → ‘망경대라는 이름을 낳게 한 조견’ → ‘조견의 형 조준’ → ‘조준이 주도한 고려말의 전제개혁’ → ‘이성계의 역성혁명’ 의 경로를 따라 여말선조(麗末鮮初)의 역사를 탐구할 수 있고, 또 다른 경우에는 ‘루도비꼬 유적지’ → ‘루도비꼬 볼리외 신부’→ ‘병인박해’ → ‘대원군’으로 이어지는 연결 고리를 좇아 조선 말기의 동서교섭사(東西交涉史)를 공부할 수도 있다.
지식과 정보는 유통 목적에 따라 그 내용 요소의 조직을 일정하게 유지할 필요도 있고, 자유로운 조합을 허용할 필요도 있다. 종래의 “종이 책”은 전자에 적합한 매체였다. 우리가 새롭게 “하이퍼텍스트”에 주목하는 이유는 그것이 과거의 정보 매체에서는 구현하기 어려웠던 후자의 기능을 열어 주고 있기 때문이다.
2. 하이퍼텍스트 기술의 발전
“관계가 있으면 연결한다”고 하는 하이퍼텍스트의 취지는 컴퓨터를 통해서만 현실화할 수 있다. 물론 종이 매체를 이용한 백과사전이나 도서관 목록 카드가 “참조: ....” 또는 “.....도 보라”라는 식으로 유관한 정보를 안내해 주는 기능을 포함하기도 하였다. 그러나 종이 매체 상에서는 참조 지시를 받을 때마다 페이지를 넘겨 유관 자료를 찾아가는 것이 결코 쉬운 일이 아니며, 그 관련성의 범위도 지극히 제한적일 수밖에 없다. 하이퍼텍스트는 ”관련 정보로의 순간적인 이동“이 가능한 경우에만 효용성을 발휘한다. 특정 정보에 대한 기록을 빠르고 정확하게 찾아내고자 하는 과제는 전자매체를 사용하는 컴퓨터 시스템을 통해 그 해결책을 찾게 되었고, 그것이 오늘날의 ”하이퍼텍스트로 짜여진 거대한 정보의 세계“- 월드 와이드 웹(World Wide Web)을 출현시킨 배경이 되었다. 이러한 점에서 진정한 하이퍼텍스트의 역사는 컴퓨터 발전의 역사와 궤적을 같이 한다고 할 수 있다.
1) 배니버 부쉬의 메멕스
하이퍼텍스트의 개념을 처음으로 제안한 사람은 제2차 세계대전 당시 미국의 대통령 과학 자문위원이었던 배니버 부쉬(Vanevar Bush, 1890-1974)였다. 당시 미국은 전쟁에서 이기기 위해 그와 관련된 제분야의 생산성을 고도화 하는 데 총력을 기울여야 하는 상황이였으며, 부쉬는 그러한 전시체제 하에서 미국의 과학 기술 연구 역량을 집결시키는 구심점 역할을 하는 인물이었다. 전쟁이 막바지로 치닫던 1945년 부쉬는 「마치 우리가 생각하는 것처럼 ...」(As we may think)이라는 제목의 글을 통해 “기억 확장기”(Memory Extender, 줄여서 Memex)라고 이름붙인 문서 관리 장치를 제안하였다. 그는 그 시대에 이미 지식이 양이 폭발적으로 증가한 사실에 주목하였고, 종래의 문서 관리 체계 - 수 많은 자료를 한 두 가지 체계에 의해 분류하고 색인을 부여한 후, 그 색인을 이용하여 필요한 자료를 찾게 하는 방법 - 로는 그 방대한 규모의 지식을 제대로 활용할 수 없다고 하는 사실을 직시하였다. 그는 인간의 사고방식이, 머리 속에 일정한 체계의 색인을 만들어 놓고 매번 그 색인을 참조하면서 생각을 전개시켜 나아가는 것이 아니며, 한 가지 생각 속에서 순간적으로 다른 생각으로 이어지는 실마리를 찾아가는 것이라도 보았다. 인간의 두뇌 밖에 있는 자료를 이용할 때에도 “마치 인간이 생각하는 것처럼” 즉각적인 연상의 실마리를 좇아 지식과 정보를 찾아갈 수 있다면 얼마나 효과적일까? 부쉬는 어떠한 기계적 장치가 자신의 꿈을 현실화할 수 있을 것으로 기대하였다.
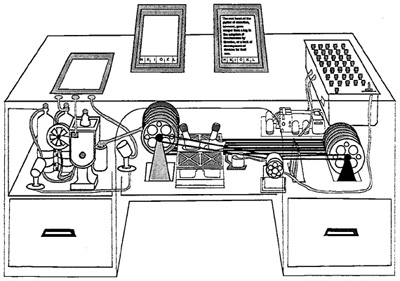
<그림 2: 배니버 부쉬가 구상한 메멕스의 모습>
2) 테드 넬슨의 하이퍼텍스트
부쉬가 “메멕스”라는 이름으로 제안한 유연한 문서 관리 체계는 그로부터 약 20년이 지나 테드 넬슨(Ted Nelson )에 의해서 “하이퍼텍스트”라는 이름을 얻게 되었다. 넬슨은 1965년 그의 저서 『리터러리 머신』(Literary Machines)에서 재나두 (Xanadu)라는 이름의 거대한 프로젝트를 제안하였다.

<그림 3: 테드 넬슨의 『리터러리 머쉰』 표지>
재나두는 전세계의 수많은 사람들이 남긴 기록들이 망라적으로 등재되어 있는 거대한 문서의 세계이다. 이곳에 있는 각종 문서들은 그 내부에 다른 유관 문서로 연결될 수 있는 고리를 갖는다. 재나두를 방문한 독자들은 그 연결 고리를 따라 자유롭게 다양한 기록들을 탐색할 수 있고, 또 그 스스로 또 다른 기록의 저자가 되어 지식과 정보의 새로운 경로를 만들어 낼 수도 있다. 오늘날의 월드 와이드 웹(World Wide Web)을 더욱 이상적으로 묘사한 듯한 이 가상 세계의 중심 개념이 바로 하이퍼텍스트이다. 넬슨은 “하이퍼텍스트”를 “비순차적인 글쓰기”(non-sequential writing)라고 정의하였다. 그 자체로는 순서 없이 존재하는 여러 개의 텍스트 조각(text chunk)이지만, 그 안에는 다른 조각으로 이어지는 다양한 연줄(link)이 있어서 독자에 선택에 따라 이렇게 이어지기도 하고 저렇게 이어지기도 하는 것을 하이퍼텍스트라고 이름한 것이다.
3) 애플사의 하이퍼카드
배니버 부쉬에 의해 창안되고, 테드 넬슨에 의해 이름을 얻게 된 “하이퍼 텍스트”는 1960년 대 후반부터 실제로 컴퓨터 상에서 구현되기 시작하였지만, 연구․개발의 차원을 넘어서서 실용화되기 시작한 것은 1980년대 중반을 지나면서부터였다. 1987년 미국의 애플사(Apple Computer, Inc.)는 자사의 매킨토시 시스템에서 사용되는 하이퍼텍스트 응용 상품 하이퍼카드(HyperCard™)를 출시했는데, 이는 사용자들의 폭발적인 호응을 얻었다. 하이퍼카드의 성공 요인은 그것이 매킨토시 컴퓨터의 운영체제와 함께 제공되는 무료 소프트웨어 패키지였다는 점, 그리고 텍스트 뿐 아니라 소리와 이미지로의 링크를 제공하여 컴퓨터의 멀티미디어적 편리성을 부각시켰다는 점이다. 하이퍼카드처럼 멀티미디어 기능을 가진 하이퍼텍스트 시스템을 “하이퍼미디어”(Hyper Media) 시스템이라고 부르기도 한다.
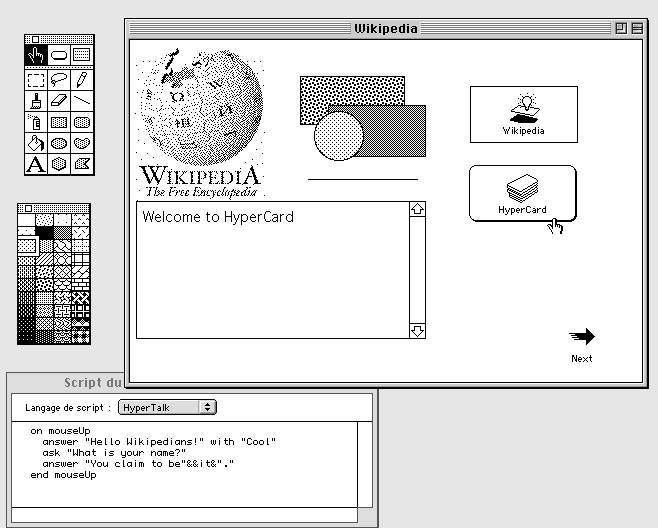
<그림 4: 애플사의 하이퍼카드>
애플사의 하이퍼카드는 하이퍼텍스트의 편리성을 널리 인식시키는 데 기여하였지만, 그것은 두 가지 점에서 명백한 한계를 갖는 것이었다. 첫째는 텍스트 조각의 연결이 “텍스트”라기보다 “카드” 단위로 이루어지도록 되었기 때문에 정보를 유연하게 다룰 수 없었던 점, 둘째는 서로 연결할 수 있는 자료의 범위가 하이퍼카드 소프트웨어의 데이터에만 한정되었다는 점이다. 그 두 번째 문제점은 상업적인 목적으로 개발된 신기술이 공통적으로 안고 있는 한계이다. 이윤을 극대화하기 위해 “독점”을 지향하고, 그로 인해 자기 것이 아닌 것에 대해서는 폐쇄적인 입장을 취하기 때문이다.
4) 월드 와이드 웹의 탄생
하이퍼텍스트를 모든 곳의 자료가 자유롭게 연결되는 길로 열어 놓은 것은 출발 단계에서부터 비영리적인 목적을 취한 작은 연구 프로젝트에서 비롯되었다. 1980년대 초부터 개인적으로 하이퍼텍스트를 연구하던 팀 버너즈리(Tim BernersLee)는 스위스 제네바에 있는 유럽 소립자 물리학 연구소(Conseil Européen pour la Recherche Nucléaire, CERN)에 취직한 후, 그 연구소에 쌓인 엄청난 양의 자료들을 세계 각처의 관련 연구자들에게 효과적으로 제공할 수 있는 방법에 대해 고민하기 시작하였다. 이 때 그가 주목한 것은 애플사의 하이퍼카드가 입증한 “하이퍼텍스트”의 편리성, 그리고 전세계의 컴퓨터를 하나의 네트워크로 연결하고 있는 “인터넷”의 개방성이었다. 1989년 버너즈리는 하이퍼텍스트와 인터넷을 결합시키는 프로젝트를 제안했고, 네트워크 전문가 카일리아우(Robert Cailliau)의 협조로 온라인 서비스상에서의 하이퍼텍스트 개념을 정립하였다. 이로써 이용자의 관심이 끌리는 대로 읽어 갈 수 있는 정보 조각들의 거대한 거미줄 망(WEB)이 탄생하게 되었으며, 그 이름은 “월드 와이드 웹(World Wide Web, WWW)으로 지어졌다. 1991년 12월 버너즈리는 미국의 산안토니오에서 열린 Hypertext '91 학술회의에서 월드 와이드 웹을 세계에 소개하였다.
3. 하이퍼 텍스트 구현 기술
우리가 “월드 와이드 웹”(World Wide Web)이라고 부르는 것의 정의는 “하이퍼 텍스트 문서를 지원하는 인터넷 서버들의 범세계적인 집합”(the global collection of Internet servers which support hypertext documents )이다. 그리고 여기서 말하는 “하이퍼 텍스트 문서”의 기술적 의미는 “HTML로 쓰여지고, HTTP를 통해 전송되는 전자 텍스트”를 말한다. HTML은 “하이퍼텍스트 표기 언어”(Hypertext Markup Language), HTTP는 ”하이퍼텍스트 전송 규약“(Hypertext Transfer Protocol)의 약어이다. HTML로 쓰여져서 인터넷 서버에 저장된 전자 문서를 우리는 통상적으로 ”웹 문서“ 또는 ”웹 페이지“라고 부른다. 하이퍼텍스트의 구현을 위해 우리가 먼저 알아야 할 것은 이러한 맥락의 ”웹 문서“의 제작 방법일 것이다.
컴퓨터 프로그래밍 기술을 가지고 있는 사람이라면 월드 와이드 웹 환경을 떠나서도 얼마든지 개인적인 용도의 하이퍼텍스트를 구현할 수 있다. 한동안 폭발적인 인기를 모았던 애플사의 “하이퍼카드”도 웹 환경과는 무관한 것이었다. 그러나 “월드 와이드 웹”이 “인터넷”과 동일시 될 만큼 큰 영향력을 발휘하는 오늘날, 웹에서 운영될 수 있는 전자문서를 제작하는 것은 곧 세계의 모든 자원과 소통할 수 있는 하이퍼텍스트 콘텐츠를 제작한다는 의미를 지니게 된다. 웹 문서를 제작하는 인구도 무수하리만큼 많기 때문에 그 편의성을 도모하기 위한 장치도 뛰어나다. 웹 문서의 제작이 하이퍼텍스트 콘텐츠 제작의 유일한 길은 아니지만, 가장 영향력 있고 손쉬운 길임은 부인할 수 없다.
1) 하이퍼 링크와 HTTP
하이퍼텍스트를 이루는 텍스트 조각들 사이의 연결을 “하이퍼 링크”(Hyper Link)라고 한다. 다음 그림은 월드 와이드 웹 환경에서 개별적인 웹 문서들 사이의 하이퍼 링크가 구현되는 과정을 개념적으로 도시한 것이다.
<그림 5: 월드 와이드 웹의 하이퍼 링크>
월드 와이드 웹을 구성하는 인터넷 서버 머신들은 다른 웹 문서로의 연결 고리를 포함하는 여러 개의 웹 문서를 저장하고 있다. 인터넷 세계의 정보를 탐색하고자 하는 이용자는 “웹 브라우저”(Web Browser) 라고 하는 소프트웨어를 이용하여 첫 번째 웹 문서를 호출한다. 요즈음 많은 사람들이 웹 검색을 위해 사용하는 “인터넷 익스플로러”(Internet Explorer™)나 그 이전에 쓰이던 “넷스케이프”(Netscape™), “모자이크”(Mosaic™) 등이 모두 “웹 브라우저”에 해당한다. 이용자 단말기에서 운영되는 “웹 브라우저”는 인터넷 서버 머신에서 운영되는 “웹 서버” 프로그램과 메시지를 주고받으면서 서버 머신에 저장된 웹 문서를 이용자 단말기로 불러 오는 기능을 수행한다. 이 때 웹 브라우저와 웹 서버 두 소프트웨어가 주고받는 신호에 대한 약속이 이른바 “하이퍼텍스트 전송 규약”, 즉 HTTP이다. 이 약속이 있음으로서 이용자 쪽의 웹 브라우저와 서버 쪽의 웹 서버가 웹 문서의 요청과 전송을 정확하게 수행할 수 있는 것이다.
첫 번째 문서를 성공적으로 불러오게 되면, 이용자는 그 문서에 포함되어 있는 다른 문서로의 연결 고리(Hypertext Link Node)를 선택함으로써 내용적 연관성이 있는 다른 문서를 호출할 수 있다. 웹 브라우저는 또 다시 HTTP에 따른 요청 신호를 해당 웹 서버로 보내고, 그 신호를 받은 웹 서버는 자기 쪽 컴퓨터에 수록된 두 번째 웹 문서를 요청자에게 전송한다.
2) HTML
월드 와이드 웹의 플렛폼은 이미 확립되어 있고, 또 그것은 누구나 참여할 수 있도록 개방되어 있으므로, 새로운 콘텐츠의 제작을 위해서 우리가 해야 할 일은 월드 와이드 웹에서 통용될 수 있는 형식의 “전자 문서”를 만드는 일이다. 이 말은 바꿔 말해, “웹 브라우저”와 “웹 서버”가 읽을 수 있는 형태의 문서를 만드는 것이라고 할 수 있으며, 더 구체적으로는 HTML로 쓰여진 문서를 만드는 것이라고 할 수 있다.
HTML은 월드 와이드 웹에서 통용되는 하이퍼텍스트 문서를 만드는 수단이다. HTML은 문서의 내용을 다양한 형태로 이용자에게 보여줄 수 있는 기능을 지원하는데, 정보 요소의 시작과 끝 부분에 “태그”(Tag)라고 불리는 표시를 부가하는 형식을 취한다. HTML 문서에서 태그로 둘러싸인 부분은 웹 브라우저 상에서 표시될 때, 그 태그가 지시하는 바에 따라 특별한 모양으로 표시된다.
<b>나팔꽃</b> ⇒ 나팔꽃 ..... 굵은 글씨로 표시
<font color="red">붉은 장미</font> ⇒ 붉은 장비 ..... 붉은 색으로 표시
HTML 태그의 대부분은 이처럼 문서의 모양을 꾸미는 기능을 지원하지만 그러한 태그들은 사실상 “하이퍼텍스트”의 본령과는 무관한 것이다. HTML 태그 가운데 HTTP에 기반한 문서간 연결을 가능케 하는 태그는 “닻”(anchor)이라는 이름을 가진, “<a> ...... </a>"라는 형태의 태그이다.
<a href=“http://www.xuanflute.com/index.html”>..... </a>
HTML의 “앵커”(<a>) 요소는 반드시 “href”라는 이름의 속성을 갖는다. ”href”는 “하이퍼텍스트 참조”(Hypertext Reference)를 의미하며, 그 속성 값으로 하이퍼 링크 목적지의 주소를 기입하게 되어 있다.
하이퍼 링크 목적지의 주소, 즉 웹 어드레스는 “하이퍼텍스트 전송 규약”(HTTP)에 의해 월드 와이드 웹 상에서 통용되는 웹 문서의 소재 정보이다. 이러한 주소 체계를 “URL“(Uniform Resource Locator)이라고 부르는데, 그 구성 요소는 다음과 같이 나눌 수 있다.
http://www.xuanflute.com/index.html
① ② ③
|
① 서버에게 요청하는 서비스의 종류 ② 서버 장비의 인터넷 주소: ③ 찾고자 하는 웹 문서의 파일 이름 |
HTML에서 하이퍼 링크를 위한 연결 고리를 “앵커”(anchor), 즉 “닻”이라고 부르는 이유는 “월드 와이드 웹”의 세계에서 이 문서를 읽다가 저 문서로 옮겨 가는 행위를 마치 대양을 항해하는 배가 이 항구에 들렸다가 다시 저 항구에 정박하는 것에 비유한 데서 비롯된다. “앵커”는 웹의 세계를 항해하는(Navigate) 배가 앞으로 “닻”을 내려야 할 곳을 지목한다. 하나의 웹 문서 속에 여러 개의 “앵커”가 포함되어 있다면, 그 항해의 다음 기착지를 여러 곳으로 제안하는 것이다. 그 중 어느 곳으로 갈지는 이용자가 선택할 것이다.
3) XML
XML(eXtensible Mark-up Language)은 문서의 구조적인 형식과 내용 요소들이 컴퓨터가 식별할 수 있는 명시적 정보로 기술될 수 있도록 하기 위한 전자문서 마크업 언어이다. 월드 와이드 웹의 표준화를 주도하고 있는 W3C(World Wide Web Consortium)는 1998년 최초의 XML 권장안을 제시하였으며, 최근에 이르기까지 여러 단계의 개선안과 함께 다양한 응용 기술의 표준화 방안을 제공하고 있다.
하이퍼텍스트와 인터넷의 만남에서 파생된 것이 HTML이라고 한다면, XML은 HTML과 “구조적인 지식 콘텐츠”의 결합을 위해 태어난 것이라고 할 수 있다.
<그림 6: XML의 탄생 배경>
<그림 6>에서 보듯이 XML은 HTML과 SGML(Standard Generalized Markup Language)의 결합으로 만들어졌다. 보다 정확하게 말한다면, HTML이 약화시켰던 SGML의 중요한 목적을 XML이 다시 회복시킨 것이다. SGML은 문서에 담긴 정보 요소와 그 요소들간의 관계를 컴퓨터가 이해할 수 있도록 만든 마크업 언어인데, 1969넌 미국의 IBM 사의 찰스 골드파브(Charles Goldfarb)와 그 동료들에 의해 GML(Generalized Markup Language)이라는 이름으로 처음 만들어졌고, 그 후 지속적으로 발전하여 1986년 국제표준기구에 의해 구조적 데이터 표현의 표준안(ISO 8876)으로 인증되었다.
XML 문서의 가장 대표적은 특성은 문서를 “문서의 구조”, “문서의 내용”, “문서의 모양” 3 가지로 분리한다는 것이다. 다음에 예시한 간단한 편지를 HTML로 만들었을 때와 XML로 만들었을 때를 비교하여 보자.
|
영이에게
당신을 사랑합니다.
2006. 3. 1 철수 |
HTML: 문서의 내용과 모양을 한꺼번에 취급
|
<html> <head> <title>편지<title> </head> <body> <font color="green">영이에게</font></br> <font color="black"> 당신을 사랑합니다.<br/> </font> <font color="magenta"><table align="center">2006. 3. 1</table></font> <font color="blue"><table align="right">철수</table></font> </body> </html> |
XML: 문서의 내용
|
<?xml version="1.0" encoding="euc-kr"?> <?xml-stylesheet type="text/xsl" href="letter.xsl"?> <!DOCTYPE 편지 SYSTEM "letter.dtd">
<편지> <수신>영이에게</수신> <본문> <문단>당신을 사랑합니다.</문단> </본문> <날짜>2006. 3. 1</날짜> <발신>철수</발신> </편지> |
DTD: 문서의 구조
|
<?xml version="1.0" encoding="euc-kr"?>
<!ELEMENT 편지 (수신, 본문, 날짜, 발신)> <!ELEMENT 수신 (#PCDATA)> <!ELEMENT 본문 (문단+)> <!ELEMENT 문단 (#PCDATA)> <!ELEMENT 날짜 (#PCDATA)> <!ELEMENT 발신 (#PCDATA)> |
XSL: 문서의 모양
|
<?xml version="1.0" encoding="euc-kr" ?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:template match="/"> <HTML> <HEAD> <TITLE>Letter Display</TITLE> </HEAD> <BODY> <xsl:apply-templates/> </BODY> </HTML> </xsl:template>
<xsl:template match="편지"> <xsl:apply-templates/> </xsl:template>
<xsl:template match="본문"> <xsl:apply-templates/> </xsl:template>
<xsl:template match="수신"> <FONT COLOR="green"> <xsl:value-of /><br/> </FONT> </xsl:template>
<xsl:template match="문단"> <FONT COLOR="black"> <xsl:value-of /><br/> </FONT> </xsl:template>
<xsl:template match="날짜"> <FONT COLOR="magenta"> <table align="center"><xsl:value-of /></table> </FONT> </xsl:template>
<xsl:template match="발신"> <FONT COLOR="blue"> <table align="right"><xsl:value-of /></table> </FONT> </xsl:template>
</xsl:stylesheet> |
위의 비교에서 알 수 있듯이 XML은 HTML이 표현하지 못하는 문서의 구조와 내용 요소의 성격을 명확하게 드러내 준다. 문서의 내용과 모양을 구분함으로써, 내용을 그대로 두고 모양만을 바꾼다거나, 모양에 손대지 않은 채 내용을 확장하고 수정할 수 있는 유연성을 높인 것도 XML 문서의 특징이다.
문서를 “내용”, “구조”, “모양”으로 구분하여 그 각각의 독립성과 유연성을 추구한 것은 XML의 전신인 SGML의 기본 사상이었다. HTML도 기본적으로는 SGML을 기반으로 만들어진 것이지만 그 기본 사상에는 충실하지 않았다. 대신 “하이퍼텍스트”라고 하는 SGML에는 없던 개념이 HTML에 도입되었고, 그것에 의해 월드 와이드 웹이 탄생하게 된 것이다. SGML을 차용하되, SGML에 얽매이지 않는 것이 HTML의 성공 요인이 되었지만, SGML에 추구한 목표의 중요성이 월드 와이드 웹의 세계에서 끝까지 무시될 수는 없었다. XML은 인터넷과 하이퍼텍스트가 결합한 곳에서 텍스트의 구조와 정보 요소까지 드러내고자 하는 취지에서 개발된 것이다.
XML의 이러한 특성 때문에 HTML로 구현된 하이퍼텍스트와 XML로 구현된 하이퍼텍스트는 큰 차이를 갖는다. 전자는 “텍스트”와 “텍스트”의 연결을 가능하게 하지만 그 텍스트 조각이 어떠한 특성을 가지고 있으며, 어떠한 의미 맥락 속에 있는 것인지에 대해서는 관심을 두지 않는다. XML에 의한 하이퍼텍스트는 하이퍼 링크의 노드 하나 하나가 정보 요소로서의 성격을 명시적으로 드러내기 때문에 그 성격에 합당한 방법으로 다양한 형태의 하이퍼 링크를 구현할 수 있다. 다음의 예시는 텍스트 속의 정보 요소가 자신의 여러가지 성격에 따라 그와 관련이 있는 외부 자원으로 링크되도록 한 것이다.
XML:
|
<참조 자원=“남한산성”><시청각 자원=“남한산성 남문”><공간 유형=“유적” 식별자=“남한산성 전역”><지명 유형=“유적”>남한산성</지명></공간></시청각></참조>은 <지명 유형=“유적”>북한산성</지명>과 함께 도성을 지키던 남부의 산성으로, 1636년 <시간 유형=“사건” 식별자=“병자호란 발생”>병자호란</시간> 당시 <인명 유형=“왕명” 식별자=“인조|仁祖|1595-1469”>인조</인명>가 45일간 항전하던 곳이다. |
웹 브라우저 상에서의 표현 및 하이퍼 링크:

<그림 7: XML 문서에서 구현한 하이퍼 링크>
XML 기반의 하이퍼텍스트 전자문서를 제작하기 위해서는 XML의 문법, 구조 정의, 표현 기법 등에 관한 다양한 기술을 습득해야 한다. XML 문서의 구조는 SGML에서부터 유래한 DTD(Document Type Definition)를 통해 정의하는 방법과 더욱 정교한 데이터 처리를 위해 새롭게 개발된 XML 스키마(Schema)를 사용하는 방법이 있다. XML 문서의 내용을 컴퓨터상에서 시각적으로 표현하기 위해서는 XML 구조를 HTML이나 다른 언어의 구조로 변환해 주는 XSLT(Extensible Stylesheet Language Transformation) 기술을 적용한다. XML 문서 내의 특정 부분을 찾아가기 위해 사용되는 경로 표기 언어인 XPath(XML Path Language)는 XML 데이터의 조작을 위해 필수적으로 알아 두어야 할 사항이다. XML 문서를 컴퓨터가 구조적인 정보로 취급할 수 있게 하는 DOM(Document Object Model), HTML의 앵커 요소보다 발전된 하이퍼 링크 기능을 지원하는 XLink(XML Linking Language), XML 문서 검색 기능의 표준화를 추구하는 XQuery(XML Query Language) 등도 XML 기반의 정보 시스템을 개발하는 데 필요한 기술들이다.
4) 하이퍼텍스트와 응용 프로그램의 결합
하이퍼텍스트를 구성하는 자료들이 독립적인 파일 형태로만 존재한다면, 그 파일 이름을 포함한 URL을 지정함으로써 하이퍼 링크를 구현할 수 있다. 그러나 상호 참조되어야 할 정보의 규모가 방대하여 그 각각을 독립적인 데이터 파일로 유지할 수 없을 경우, 데이터베이스에 그 정보를 수록하여 활용하는 방법을 강구해야만 한다.
데이터베이스란 “다수의 응용 시스템들이 사용할 수 있도록 통합하여 관리되는, 상호 관련성이 높은 데이터의 집합”이다. 데이터베이스에 수록된 데이터는 “데이터베이스 관리 시스템”(Database Management System, DBM,S)이라는 소프트웨어를 통해서, 또는 DBMS와 연동하는 응용 프로그램을 통해서 조작할 수 있다. 따라서 데이터베이스에 수록된 정보를 하이퍼텍스트의 구성 요소로 삼고자 한다면, DBMS나 응용 프로그램을 움직일 수 있는 명령을 하이퍼 링크 속에 담아야 한다.
다음의 예문에서 하이퍼텍스트와 응용 프로그램을 결합시킨 사례를 보기로 한다.
|
원균 |
콘텐츠 제작자는 이 문장에 포함된 세 가지 정보 요소, “원균”, “이순신”이라는 두 명의 인물 이름과 “통제사”라는 용어를 하이퍼 링크 노드로 삼고자 한다. 그런데 이 세 요소에 연결될 정보는 독립된 웹 문서 파일로 존재하는 것이 아니라 수 만 건 이상의 데이터가 종합적으로 수록된 “인명 데이터베이스”와 “관직명 데이터베이스” 안에 들어 있다. 관련 데이터베이스의 참조를 고려한 세 가지 요소의 XML 태깅은 다음과 같다.
|
<인명 유형=“성명” 식별자=“원균|元均|1540-1597|무인”>원균</인명> <인명 유형=“성명” 식별자=“이순신|李舜臣|1545-1598|무인>이순신</인명> <관직 식별자=“조선|통제사|統制使”>통제사</관직> |
각각의 요소 속에 “식별자” 속성으로 기입된 내용은 데이터베이스 상에서 해당 정보를 검색할 때 사용할 키워드이다. 이러한 형태로 만들어진 XML 데이터는 웹 브라우저 상에서 이용자에게 보여질 때 스타일 쉬트에 지정한 바에 따라 다음과 같이 변환된다.
|
<a title="인물:원균" onfocus="blur();" href="Javascript:indexLink_PPL('원균_元均_1540_1597_무인');"><span class="con_person">원균</span></a> <a title="인물:이순신" onfocus="blur();" href="Javascript:indexLink_PPL('이순신_李舜臣_1545_1598_무인');"><span class="con_person">이순신</span></a> <a title="관직:통제사" onfocus="blur();" href="Javascript:indexLink_POS('조선_통제사_統制使');"><span class="con_post">통제사</span></a> |
XML에서 HTML로 변환된 데이터 상에서 각각의 하이퍼 링크 노드는 데이터베이스를 조작하는 응용 프로그램을 호출할 수 있는 명령으로 변환되었다. 이용자가 웹 브라우저에 표시된 인명 또는 관직명을 클릭하면 웹 서버와 연동하는 응용 프로그램이 지정된 데이터베이스에서 검색 기능을 수행하여 관련 정보를 찾아내고 그 결과를 웹 문서 형태로 만들어서 이용자에게 전송할 것이다.
이용자 웹 브라우저 상에서 URL 형태로 전송한 요청을 받아들여 그것을 별도의 외부 프로그램에 넘겨 처리하고, 그 결과에 따라 응답을 해 주는 기능을 “공통 관문 인터페이스”(Common Gateway Interface, CGI)라고 한다.
<그림 8: CGI를 이용한 동적 하이퍼텍스트의 구현 모델>
CGI는 서버 쪽에서 운영되는 소프트웨어이지만 시스템의 목적에 따라 기능이 달라지는 일종의 응용 프로그램이므로 콘텐츠의 개발자에 의해 설계되고 구현되어야 한다. PHP(Professional HTML Preprocessor), JSP(Java Server Pages), ASP(Active Server Pages) 등은 CGI 구현을 위한 기술이다. 콘텐츠 개발자가 데이터베이스 수록 정보를 활용하는 동적 하이퍼텍스트를 구현하기 위해서는 스스로 이러한 기술을 습득하거나, 적어도 그 기술을 전문적으로 지원하는 정보 기술자와 자유롭게 의견을 교환할 수 있는 수준의 지식을 배양할 필요가 있다.
4. 하이퍼텍스트 기획의 유의점
인문 분야의 디지털 콘텐츠가 반드시 “하이퍼텍스트”적이어야 할 필요는 없다. 하지만 이것은 디지털 세계에서 지식과 정보의 무한한 확장을 가능케 하는 효과적인 방법이기 때문에, 종래의 아나로그 콘텐츠와 차별화된 저작물을 만들고자 하는 사람들은 이것의 응용을 고려하지 않을 수 없다.
인문 지식을 소재로 하는 하이퍼텍스트를 구현할 때 가장 먼저 유념해야 할 사실은 우리가 만들고자 하는 콘텐츠의 성격에 따라 하이퍼텍스트에 대한 의존도를 달리 가져가야 한다는 것이다. 만일 콘텐츠의 소재가 이미 일정한 줄거리를 갖고 있거나, 변화할 수 없는 계층적 체계 속에 담겨야 하는 것이라면, 하이퍼텍스트의 적용은 본문에 대한 주석문의 참조나 관련 자료로의 연결, 또는 목차와 본문의 연결 등에 국한되게 될 것이다. 이에 반해 콘텐츠의 줄거리를 독자가 만들어가도록 하는 “비순차적 글쓰기”의 도구로서 하이퍼텍스트를 이용하고자 한다면 본문 텍스트 그 자체를 여러 개의 텍스트 조각으로 나누고 그 각각에 대해 다양한 경로로의 연결 고리를 부여하는 방법을 추구해야 할 것이다.
하이퍼 링크의 범위를 자기 저작물 내에 한정할 것인가, 아니면 월드 와이드 웹의 세계에 무수히 산포되어 있는 외부 자원으로의 길도 열어 놓을 것인가 하는 것도 고심해야 할 문제이다. 또한 하이퍼 링크의 대상을 정적인 자원에 한정할 것인가, 동적으로 개방할 것인가, 다시 말해 확실하게 존재하는 특정 문서만을 찾아가게 할 것인지, 언제든 새로운 문서가 생기면 그것으로도 갈 수 있게 할 것인지를 결정하는 것도 중요한 일이다.
이 모든 문제에 관한 의사결정은 콘텐츠의 내용과 기획 의도, 활용 목적에 따라 달라질 것이다. 어떠한 소재를 다루든, 활용성이 높은 양질의 디지털 콘텐츠를 만들고자 한다면 다양한 형태의 하이퍼 링크를 자유롭게 구사할 수 있는 기술을 습득해야 한다. “인문 콘텐츠”는 인문 지식과 정보 기술의 학제적 결합을 통해 만들어진다는 사실에 유념하면서, 인문 지식의 디지털화에 도움이 되는 정보 기술적 요소들에 대한 이해의 폭을 넓혀 가야 할 것이다. (김현, 한국학중앙연구원 교수, 인문정보학)
김현은 고려대학교 철학과를 졸업하고 같은 대학 대학원에서 박사 학위를 받았다. 전자통신연구원(ETRI) 뉴미디어정보시스템연구실장, 서울시스템(주) 한국학데이터베이스 연구소장, 미국 하버드 대학 방문연구원, 한국과학기술정보연구원(KISTI) 정보시스템 부장을 역임하였고, 현재 한국학중앙연구원 인문정보학 담당 교수로 재직하고 있다. 1995년 『국역 조선왕조실록 데이터베이스 CD-ROM』간행을 비롯하여 현재의 『한국향토문화전자대전』 편찬 사업에 이르기까지 인문 지식 자원을 소재로 한 다수의 정보 시스템을 개발하였으며, 인문과학과 정보과학의 학제적 교섭을 지향하는 “인문정보학”의 이론적 토대를 마련하는 연구를 수행하고 있다.